

Un modelo de lenguaje no “sabe” todo lo que responde: lo recupera. Y la metadata es la brújula silenciosa que decide qué encuentra, qué descarta y qué termina citando.
Cuando le haces una pregunta a una LLM y te responde con un dato preciso una fecha, una cifra, una cita de un documento es fácil imaginar que el modelo “lo tenía guardado”. La realidad es más interesante: en la mayoría de los sistemas modernos, el modelo sale a buscar esa información en el momento, la recupera de una base de datos y recién entonces redacta la respuesta. Ese proceso de búsqueda se apoya en una pieza poco glamorosa pero decisiva: la metadata.
Entender cómo una LLM busca es clave para cualquiera que produzca contenido hoy. Ya no escribes solo para que un humano te lea o para que el algoritmo azul de Google te posicione: escribes para que un sistema de inteligencia artificial pueda encontrarte, entenderte y citarte. Y la diferencia entre ser encontrado o ignorado muchas veces está en datos que el lector jamás ve.
01 Una LLM no busca como Google
El buscador tradicional funciona, en esencia, por coincidencia de palabras: tú tecleas “terrenos en venta Puebla” y el motor te devuelve páginas donde aparecen esas palabras, ordenadas por cientos de señales de autoridad. Es un emparejamiento entre cadenas de texto.
Una LLM trabajó distinto desde el principio. No compara palabras: compara significados. Para lograrlo necesita convertir el lenguaje en números, y ahí entra el primer concepto fundamental.
02 Embeddings: convertir significado en coordenadas
Un embedding es una representación numérica de un texto: un vector de cientos o miles de números que captura su significado. Frases parecidas en sentido aunque usen palabras distintas terminan con vectores cercanos entre sí. “Comprar un lote de inversión” y “adquirir un terreno con plusvalía” no comparten casi ninguna palabra, pero quedan vecinos en ese espacio matemático.
Buscar, entonces, se convierte en un problema geométrico: el sistema transforma tu pregunta en un vector y luego encuentra los fragmentos de texto cuyos vectores están más cerca. A eso se le llama búsqueda semántica o búsqueda por vecinos más cercanos. significado → lote · terreno · plusvalía tu pregunta cocina · recetas Los textos con significado parecido quedan cerca; los irrelevantes, lejos.

Figura 1. Búsqueda semántica: la pregunta se ubica en un espacio de significados y atrae a los fragmentos más cercanos.
El flujo completo: RAG paso a paso
La arquitectura más común que conecta una LLM con información externa se llama RAG (Generación Aumentada por Recuperación, por sus siglas en inglés). Suena complejo, pero el flujo es sencillo y vale la pena verlo entero.
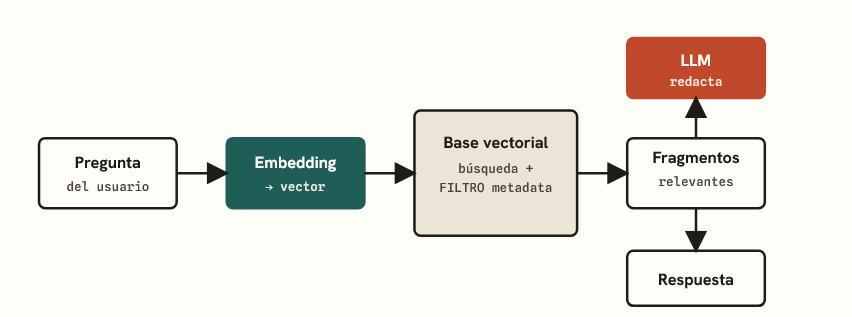
Figura 2. Pipeline RAG. El paso decisivo ocurre dentro de la base vectorial, donde el filtro de metadata recorta el universo antes de comparar significados.
Lo importante: la LLM nunca ve la base de datos completa. Solo recibe un puñado de fragmentos los más relevantes y construye la respuesta a partir de ellos. Si esos fragmentos están mal seleccionados, la respuesta será pobre por más potente que sea el modelo. Por eso la calidad de la recuperación importa tanto como la del modelo.
04 Aquí entra la metadata
Cuando un sistema prepara documentos para que una LLM los pueda consultar, los parte en pedazos llamados chunks (fragmentos). Cada fragmento se convierte en un embedding… pero también se le adjuntan etiquetas descriptivas: eso es la metadata.
La metadata no es el contenido en sí, sino datos sobre el contenido: de qué fuente viene, cuándo se publicó, quién lo escribió, de qué tema trata, en qué idioma está, qué tipo de documento es. Pensá en ella como la ficha bibliográfica pegada a cada fragmento.
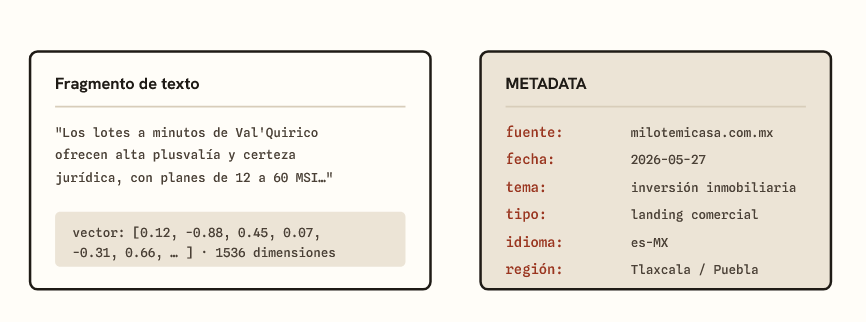
Figura 3. Anatomía de un fragmento: el texto se vuelve vector para la búsqueda semántica, y la metadata viaja adjunta como ficha de identidad.
¿Por qué importa tanto? Porque la metadata permite filtrar antes de comparar significados. Imagina una base con un millón de fragmentos. Si el usuario pregunta por algo reciente sobre el mercado mexicano, no tiene sentido comparar su pregunta contra fragmentos de 2018 escritos en otro país. El filtro de metadata descarta de golpe el 95% irrelevante, y la búsqueda semántica trabaja solo sobre lo que sí aplica. Resultado: respuestas más precisas, más rápidas y más baratas de procesar.
05 Búsqueda híbrida: significado + filtros
Los sistemas serios rara vez usan solo búsqueda semántica. Combinan tres capas que se complementan, en lo que se conoce como búsqueda híbrida:
- Filtro de metadata: recorta el universo a lo que cumple condiciones duras (fecha, región, fuente, permisos).
- Coincidencia léxica: rescata términos exactos —nombres propios, códigos, marcas— que la semántica a veces difumina.
- Coincidencia semántica: ordena por cercanía de significado los candidatos que quedaron.
Al final suele intervenir un reranker: un segundo modelo que reordena los finalistas para dejar arriba lo verdaderamente útil. Es como un embudo donde cada etapa afina lo que pasa a la siguiente.
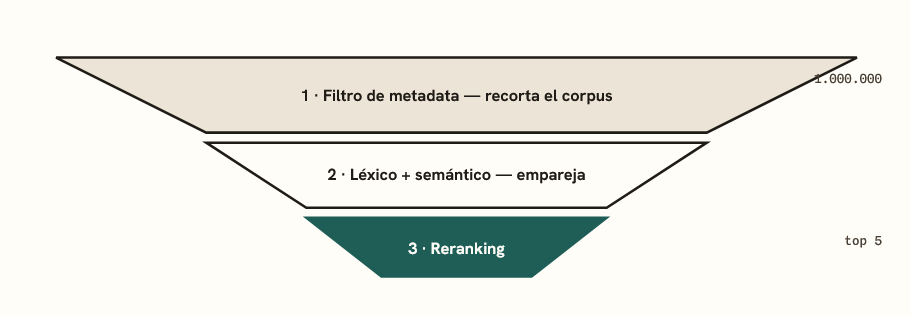
Figura 4. El embudo de la búsqueda híbrida: de un millón de fragmentos a los cinco que la LLM realmente leerá.
“El modelo es el chef, pero la recuperación es quien decide qué ingredientes entran a la cocina. Y la metadata es la lista de quién puede pasar.”
06 ¿Y los buscadores con IA de tu sitio web?
Todo lo anterior ocurre dentro de sistemas cerrados, pero la misma lógica se traslada a la web abierta. Cuando ChatGPT, Perplexity, Gemini o los resúmenes con IA de Google rastrean internet para responder, también dependen de metadata… solo que la tuya, la que vive en tu página.
Aquí la metadata toma formas muy concretas que tú sí controlas:
- Datos estructurados (Schema.org): le dicen a la máquina “esto es un producto”, “esto es una FAQ”, “esto es una organización con esta dirección”. Es metadata explícita y legible por IA.
- Etiquetas meta: el title, la meta description y las etiquetas Open Graph resumen de qué trata la página antes de leer una sola línea del cuerpo.
- Encabezados y jerarquía: tus H1, H2 y H3 funcionan como mapa del contenido; ayudan a fragmentar la página en chunks coherentes.
- Señales de frescura y autoría: fechas de publicación y actualización, autor, fuente. La IA prioriza lo reciente y lo atribuible.
A esta nueva disciplina —optimizar para que los sistemas generativos te encuentren y te citen— se le llama GEO (Generative Engine Optimization). No reemplaza al SEO: lo complementa. El SEO clásico te posiciona en una lista de enlaces; el GEO busca que tu contenido sea el fragmento que la IA elige para construir su respuesta.
En una frase
Una LLM no premia la página “más bonita” ni la más larga: premia la que está mejor descrita. La metadata es la forma en que tu contenido se presenta a una máquina que no tiene tiempo de leerlo todo.
07 Qué hacer con esto si produces contenido
La conclusión práctica es alentadora, porque casi todo está bajo tu control y no requiere reescribir tu sitio entero. Empieza por lo de mayor impacto:
- Escribe títulos y descripciones que digan qué es y para quién, no frases poéticas vacías. La máquina las usa como primer filtro.
- Marca tu contenido con datos estructurados acordes a lo que ofreces: producto, servicio local, artículo, preguntas frecuentes.
- Sé explícito con fechas, ubicación y autoría. “Terrenos en Tlaxcala, actualizado en 2026” le da a la IA exactamente las etiquetas que necesita para filtrar.
- Estructura con encabezados claros y párrafos autocontenidos: cada sección debería entenderse sola, porque puede ser recuperada sola.
- Responde preguntas reales de forma directa. Los fragmentos que contestan una intención concreta se recuperan y citan mejor que los textos genéricos.
Durante años optimizamos el contenido para un algoritmo que ordenaba enlaces. Hoy escribimos, además, para sistemas que leen, comprenden y resumen. El cambio de fondo es este: la información ya no solo necesita estar bien escrita, necesita estar bien etiquetada. La metadata dejó de ser un detalle técnico de programadores para convertirse en parte del mensaje. Quien la entienda, será encontrado. Quien la ignore, será invisible para la próxima generación de búsqueda. Visita a los expertos: https://aalcuadrado.com.mx/
